O QUE É O APACHE HADOOP
ESTRUTURA HADOOP
Segundo Carmen Placios a arquitetura das versões do Hadoop 0 e 1 se dividem em três pilares fundamentais:
- Hadoop MapReduce: que podemos definir como o motor ou modelo de programação que impulsiona o Hadoop.
- Sistema de arquivos: Hadoop utiliza seu próprio sistema de arquivos distribuídos, denominado Apache Hadoop Distributed File System (HDFS).
- Hadoop Common: utilitários que possibilitam a integração dos subprojetos do ecossistema Hadoop.
Durante o processo de amadurecimento do Apache Hadoop um quarto pilar, denominado Yarn, foi inserido a partir da versão 2 (Apache, 2012):
Hadoop Yarn: pode ser considerado a evolução do MapReduce, ou MRv2 como veremos mais adiante.
MAPREDUCE
Uma aplicação MapReduce em execução no Hadoop recebe seu trabalho dividido entre os nós – computadores que formam um cluster geralmente são chamados de nós – e os arquivos a serem manipulados pela aplicação residem no sistema de arquivos, HDFS, o que mantém a entrada e saída a um baixo custo (deRoss; et al, 2014).
Em linhas gerais, o Hadoop fragmenta os dados no seu sistema de arquivos quando a função map é utilizada e destes fragmentos são geradas tuplas formadas por (chave, valor) produzindo um novo conjunto de chaves e valores intermediários e aplica a função shuffle para classificar todos os valores iguais a uma mesma chave para reduzir as tarefas. Em sequência os nós executam a função de redução e processam as tuplas geradas pela função shuffle produzindo uma tupla única para cada valor e chave correspondentes. A função de redução também se encarrega de escrever as saídas de dados no sistema de arquivos distribuído. Para exemplificar todo esse processo, vamos observar a imagem 1:
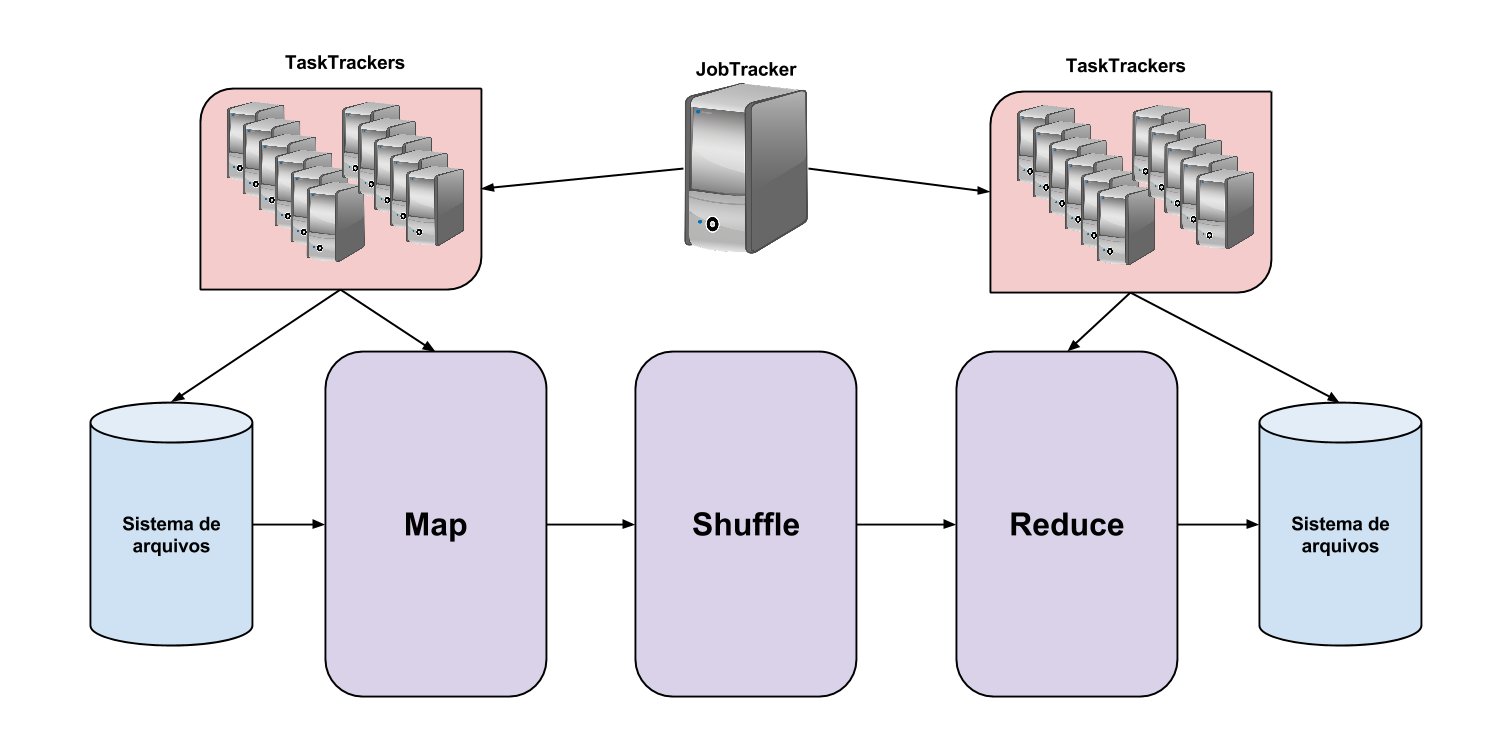
Fonte: Adaptado de Apache, 2014
Como podemos ver, existe um único nó, denominado JobTracker, que se encarrega de delegar as funções de mapeamento e redução para os demais nós, chamados de TaskTrackers.
HDFS
Como vimos o MapReduce segue sua hierarquia de nós e com o HDFS não é diferente. Existe o NameNode, ou master, que é responsável pelo controle de acesso, organização dos diretórios e metadados. Os DataNodes, ou workers, que são responsáveis pelos fragmentos de arquivos e suas replicações, como podemos ver na imagem 2:
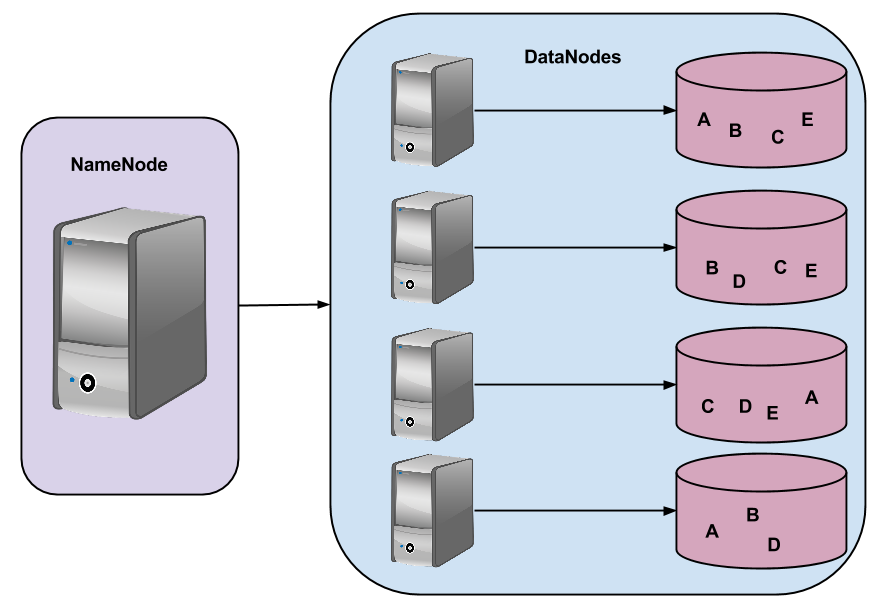
Fonte: Adaptada de Apache 2014
As letras usadas (A, B, C e D) representam fragmentos de arquivos divididos entre os nós para garantir redundância e tolerância a falhas no sistema de arquivos (White, 2014).
YARN
Como dito anteriormente, o Yarn é uma evolução do MapReduce onde as funções do JobTracker são repartidas em deamons independentes. Uma das funções principais do MapReduce é a de partilhar os dados para as funções de Map e Reduce, a outra função é gerenciar as falhas e procurar nós disponíveis para executar a função onde houve falha. Para isso o Yarn muda um pouco a nomenclatura do nó master e o apelida de Resource Manager (RM) ou Application Master (AM), onde cada função MapReduce é uma aplicação definida pelo nó mestre e o resource manager fica responsável por reordenar os nós no caso de falhas dos nós escravos, NodeManager (NM). (Apache, 2014)
HADOOP COMMOM
Por trás do Hadoop não existem só o MapReduce e HDFS, existe um ecossistema com mais de uma dezena de projetos relacionados e que podem facilitar atividades e a configuração de um cluster. Em grande parte projetos do ecossistema também são hospedados pela Apache Software Foundation (deRoss; et al, 2014) e agora veremos alguns dos principais projetos (Apache, 2014):
- Ambari: um framework web para construção, monitoramento e manutenção de um cluster Hadoop, fornecendo uma interface amigável para tais funções e uma sessão para inclusão ou exclusão de nós escravos. Disponível em: http://ambari.apache.org
- Avro: um sistema para serialização de dados, compactando-os em formato binário. Disponível em: http://avro.apache.org
- Cassandra: um banco de dados que preza por escalabilidade, alta disponibilidade e tolerância a falhas para hardware commodity. Disponível em: http://cassandra.apache.org
- Chukwa: um framework escalável para análises de logs. Disponível em: http://chukwa.apache.org
- Hbase: um banco de dados escalável, distribuído, que suporta o armazenamento de dados estruturado para grandes mesas. Disponível em: http://hbase.apache.org
- Hive: uma infraestrutura para Datawarehouse que tem como característica um compactador próprio e um sistema para consultas ad hoc. Disponível em: http://hive.apache.org
- Mahout: um framework escalável para machine learning e data mining. Disponível em: http://mahout.apache.org
- Pig: uma plataforma para análise de grandes conjuntos de dados que roda sobre o HDFS, como um compilador próprio para produzir programas de MapReduce usando uma linguagem de programação chamada Pig Latin. Disponível em:http://pig.apache.org
- Sqoop: uma ferramenta para mover dados de bases relacionais para o HDFS.
- ZooKeeper: um framework coordenador de computação distribuída altamente confiável, como nomes, configuração e sincronização entre os nós. Disponível em: http://zookeeper.apache.org

CARACTERÍSTICAS DO HADOOP
Como dito anteriormente o Hadoop é um sistema tolerante a falhas, com grande confiabilidade e alta escalabilidade e para exemplificar podemos usar como exemplo um programa que roda em um único computador. Quando o programa falha, ele simplesmente finaliza, mas em um sistema distribuído a noção de falha se faz parcial, pois somente um único nó pode falhar, ou um conjunto deles. Sobre a grande confiabilidade pode-se afirmar que um cluster deve funcionar durante um grande período de tempo sem interrupções (Tanenbaum & Steen, 2010).
A alta escalabilidade do Hadoop é referente a facilidade de administração quanto a inserção de novos nós para crescimento (Shvachko, 2010). O que pode aumentar seu poder de processamento de forma simples e barata, pois o Hadoop usa hardware commodity (White, 2014).
INSTALAÇÃO DO MODO SINGLE-NODE
Foi executado download da versão stable do Hadoop (2.6.0 – atual em 13/abril/2014). Disponível em:
Logo após nós podemos descompactar:
# tar xvvf hadoop*
E mover para /usr/local/hadoop (o local recomendado por convenção):
# mv hadoop* /usr/local/hadoop
2. Instalação em outras distribuições:
No caso, eu uso Arch Linux. Então para instalar no Arch:
# yaourt -S hadoop
Existem maneiras simples para executar a instalação no Debian, Ubuntu, Fedora etc. a partir de alguns repositórios.
3. Variáveis de ambiente:
A configuração da variável do Java (ao meu ver) é um pouco chata, então para evitar essa “maldição” podemos configurar o hadoop-env.sh:
# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
E faremos a seguinte alteração na linha 25:
export JAVA_HOME=[Caminho-de-instação-do-seu-Java]
No meu caso:
4. Variável Hadoop
Para facilitar o manuseio dos arquivos do Hadoop, podemos criar algumas variáveis úteis ao bash, como:
HADOOP_BIN=/usr/local/hadoop/bin
HADOOP_SBIN=//usr/local/hadoop/sbin
E para executarmos o Hadoop de maneira simples, podemos criar uma direta ao executável do Hadoop:
Pronto! Seu Hadoop está instalado com sucesso, suas variáveis estão configuradas de uma maneira inteligente. Agora temos que executar um teste básico, só pra verificar como as coisas estão.
Teste:
$ mkdir input
$ cp $HADOOP_INSTALL/hadoop/etc/hadoop/*.xml input
$ hadoop jar $HADOOP_INSTALL/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output ‘dfs[a-z.]+’
$ cat output/*
Se tudo aconteceu com sucesso, e apareceram algumas boas palavras na tela, parabéns, está tudo feito com sucesso.
INSTALAÇÃO DO MODO PSEUDO-DISTRIBUÍDO
Por default todas as jobs do Hadoop são executadas pelo usuário 0 (root) e se você deseja que as operações sejam executadas em um user específico você pode setar em /etc/conf.d/hadoop alterando a linha:
E em seguida temos que configurar os XMLs do Hadoop e o SSH.
Os arquivos XML estão localizados em /usr/local/hadoop/etc/hadoop.
Logo após, juntei aqui arquivos básicos de configuração para subir e derrubar os serviços.
1. Arquivos de configuração:
core-site.xml:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_store/hdfs/datanode</value>
</property>
</configuration>
mapred-site.xml:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value> org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Configuração SSH:
# ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# ssh-keyscan -H localhost, localhost >> ~/.ssh/known_hosts
# ssh-keyscan -H localhost, 0.0.0.0 >> ~/.ssh/known_hosts
Criação do script para subir os serviços:
# $HADOOP_INSTALL/hadoop-2.6.0/sbin/start-dfs.sh
# $HADOOP_INSTALL/hadoop-2.6.0/sbin/start-yarn.sh
# $HADOOP_INSTALL/hadoop-2.6.0/sbin/mr-jobhistory-daemon.sh start historyserver
Criação do script para derrubar os serviços:
# $HADOOP_INSTALL/hadoop-2.6.0/sbin/mr-jobhistory-daemon.sh stop historyserver
# $HADOOP_INSTALL/hadoop-2.6.0/sbin/stop-yarn.sh
# $HADOOP_INSTALL/hadoop-2.6.0/sbin/stop-dfs.sh
Teste de funcionamento: acesse http://localhost:8088
INSTALAÇÃO DO MODO TOTALMENTE DISTRIBUÍDO
Existem poucas diferenças entre a configuração do pseudo-distribuído e o modo completamente distribuído. Na verdade, o Hadoop só precisa estar instalado em todos os nós do nosso cluster e podemos fazer isso de uma maneira muito simples:
# rsync -avxP /usr/local/hadoop root@[ip_do_cliente]:/usr/local/hadoop
Mas para que isso aconteça de uma maneira transparente temos que configurar o SSH do server, para autenticação sem senha, em todos os outros nós que farão parte do nosso cluster como visto anteriormente.
Os arquivos XML tem algumas pequenas modificações:
core-site.xml – aqui definimos o uso do HDFS e o endereço do seu master e a porta que será usada:
<property>
<name>fs.defaultFS</name>
<value>hdfs://NOME_DO_SEU_MASTER:9000</value>
</property>
</configuration>
hdfs-site.xml – aqui está sendo definido o numero de replicações de cada arquivo do HDFS:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mapred-site.xml – aqui passamos a bola do gerenciador de MapReduce para o Yarn e dizemos quem vai ser o Master para distribuir tarefas:
<property>
<name>mapred.job.tracker</name>
<value>NOME_DO_SEU_MASTER:5431</value>
</property>
<property>
<name>mapred.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>NOME_DO_SEU_MASTER:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>NOME_DO_SEU_MASTER:8035</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>NOME_DO_SEU_MASTER:8050</value>
</property>
</configuration>
Todos os outros nós precisam estar nomeados no seu /etc/hosts, como por exemplo:
hadoopslave1 [IP]
hadoopslave2 [IP]
hadoopslave3 [IP]
hadoopslave4 [IP]
hadoopslave5 [IP]
hadoopslave6 [IP]
hadoopslave7 [IP]
hadoopslave8 [IP]
hadoopslave9 [IP]
Agora, dois novos arquivos precisam ser criados dentro de /usr/local/hadoop/etc/hadoop. slaves – que são todos os computadores que farão parte do nosso cluster como “clientes”:
hadoopslave2
hadoopslave3
hadoopslave4
hadoopslave5
hadoopslave6
hadoopslave7
hadoopslave8
hadoopslave9
master – que é o computador responsável pelo gerenciamento dos nós:
Teste de funcionamento: acesse http://localhost:8088
REFERÊNCIAS
- Tom White – Hadoop the definitive guide
- Chuck Lam – Hadoop in action
- Dirk deRoos, et al – Hadoop for dummines
- Sistemas distribuídos – TeS
Artigo: MaCarmen Palacios Díaz-Zorita – Evaluación de la herramienta de código libre Apache Hadoop
Sites:
- Hadoop – Apache Hadoop 2.6.0
- Scalability of the Hadoop Distributed File System | Konstantin V. Shvachko – Yahoo
- Re: [VOTE] – Establish YARN as a sub-project of Apache Hadoop
- Imagem
Instalação: